
Luigi Jones y las peticiones perdidas
Tontamente llevo ya 5 años trabajando con arquitecturas de microservicios y durante todo este periplo más de una vez he echado de menos la simplicidad del monolito. Este no es un post sobre si debes o no meterte en el fregao de las arquitecturas de microservicios (la respuesta corta es NO, salvo que haya más de dos equipos trabajando en la misma aplicación y tengas muy claro cuáles son los dominios de negocio) sino de una vez que estás metido ya en faena.
Así que voy a coger el fedora, la cazadora y el látigo del Dr. Jones y empezamos la aventura.
Acto I
Resulta que te has decidido a montar una arquitectura de microservicios. Cuando ya la tienes corriendo y funcionando es cuando empiezan los problemas de verdad ![]() Van a salir errores, se van a caer servicios, vas a tener cuellos de botella, van a ir las cosas lentas, la aplicación dejará de funcionar, llegarán las quejas de los clientes… y ya no hay un úncio sitio donde tienes que mirar, ahora tienes X microservicios y tienes que saber en cuál de ellos está la causa del fallo.
Van a salir errores, se van a caer servicios, vas a tener cuellos de botella, van a ir las cosas lentas, la aplicación dejará de funcionar, llegarán las quejas de los clientes… y ya no hay un úncio sitio donde tienes que mirar, ahora tienes X microservicios y tienes que saber en cuál de ellos está la causa del fallo.
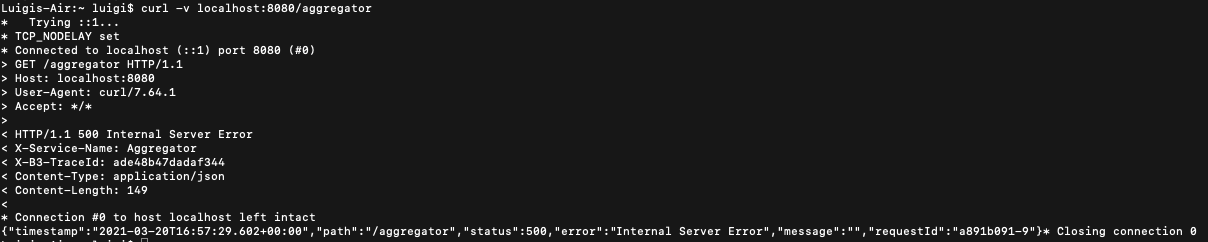
Y claro, si tienes un proceso complejo en el que intervienen 6 microservicios diferentes y tu mejor pista es un 500 Internal Error… lo tienes chungo. Puedes empezar en orden viendo el primer endpoint por donde ha entrado la petición y resulta que tienes suerte: la primera llamada que haces es la que ha dado el 500 y piensas “¡Hurra! ya se dónde está el error” y llamas al equipo que se encarga del microservicio de esa primera llamada:
- ¡Hola! Cuando os llamamos estáis dando un error, ¿podéis mirar a ver qué está pasando?
- Anda, ¿ha fallado algo? primera noticia que tenemos. ¿Cuándo ha pasado?”
- Pues ha sido sobre las 10 y media de hoy, hora zulú.
- Mmm… ¡ostras! Pues resulta que entre las 10:20 y las 10:40 hemos tenido 5000 peticiones que han fallado. ¿Sabes cuál podría ser la tuya?
- WTF! ![]()
Y aquí es donde empieza la fiesta, en el mejor de los casos van a pasar días hasta encontrar la causa del problema y mientras tanto tienes el teléfono que echa humo de clientes enfadados porque no pueden comprar en tu flamante marketplace.

Acto II
Por suerte en el mundo real esto no pasa nunca (MUHAHAHAHAHA) y hay herramientas que puedes y debes usar para evitar la hecatombe. Salvo que seas un loco trapecista que vive al límite sin usar la red vas a necesitar (al menos) trazabilidad distribuida, un agregador de logs y un sistema de monitorización y alertas. Y si de alguien he aprendido mucho de estos temas es del señor Juan “50 latigazos” Fernandez-Corugedo, un auténtico maestro en la materia que seguramente dentro de poco nos deleite con un post sobre monitorización y performance, no duden en seguirlo.
Actualmente hay varias herramientas que te ayudan con cada una de estas materias:
- Monitorización y alertas: Prometheus, Grafana, Datadog, Dynatrace, Nagios, …
- Agregadores de logs: ELK, GrayLog, Loggly, Fluentd, …
- Trazabilidad distribuida: Opentracing, Sleuth, Zipkin, Jaeger, …
Hoy me voy a centrar en la trazabilidad distribuida con Sleuth + Zipkin por su sencillez de implementación en aplicaciones SpringBoot.
¿Y qué vamos a conseguir con esto? Un identificador único por petición (Trace ID) con el que poder rastrearla por distintos microservicios. De este modo la próxima vez que algo falle, cogerás tu identificador, entrarás en la heramienta de trazabilidad, verás el microservicio que ha desencadenado el error y llamarás directamente a ese equipo:
- Hola, tenemos un error en la petición “xa12345-feeedd” ¿nos podéis decir por qué ha fallado?
- A ver déjame que la busque en mis logs… anda pues nos habéis enviado una cadena alfanumérica en el campo “OrderNumber” y solo aceptamos cadenas numéricas.
- ¡Ups! nos habían dicho que ahí podía ir cualquier cosa. Vale, pues vamos a cambiarlo, ¡¡¡muchas gracias!!!
- De nada y que pase un buen día.

Acto III
Para ver la utilidad de la trazabilidad distribuida he creado una aplicación dinopark que va a hacer uso de varios microservicios y vamos a ir viendo cómo con zipkin podemos ver por dónde va pasando cada petición.
El proyecto se compone de los siguientes componentes:
- Un visualizador de peticiones con una imagen docker de zipkin donde se van a ir registrando por dónde pasa cada petición y donde podemos verlo gracias a su interfaz gráfica.
- Un service discovery con eureka en el que vamos registrar los microservicios para que quien vaya a usarlos no tenga que conocer sus ips: otra de las piezas claves en una arquitectura de microservicios si quiere ser escalable. En un primer intento intenté usar una imagen docker de eureka de las que había por ahí, pero había problemas con la versión que estaba usando en los microservicios para registrarse, así que opté por montar mi propio servicio y todo empezó a funcionar a las mil maravillas.
- dinosaurs: Un microservicio con springboot que da la información de la lista de dinosaurios que hay en el dinopark.
- triceratops: Un microservicio con springboot que da la información sobre los triceratops del dinopark.
- aggregator: Un microserivicio reactivo con springboot y webflux que hace de agregador recuperando la información de los dinosarios del dinopark (va a llamar a dinosaurs y triceratops).
Como veis es un pequeño ejemplo de lo que se puede llegar a hacer y el dinopark podría tener muchos más microservicios, pero para mostrar la utilidad de la trazabilidad distribuida en esta prueba de concepto son suficientes.
Está todo dockerizado para facilitar su arranque, así que primero arrancamos las dependencias (eureka y zipkin) y luego los servicios del dinopark (triceratops, dinosaurs y aggregator) gracias al docker-compose.

Acto IV
Ya tenemos todo arrancado, los microservicios se han registrado correctamente en el service discovery y estamos listos para hacer la primera petición al aggregator para saber qué dinosaurios tenemos en el dinopark. Lanzamos la petición y obtenemos la respuesta ¡¡perfect!!
Veamos en zipkin qué ha pasado:
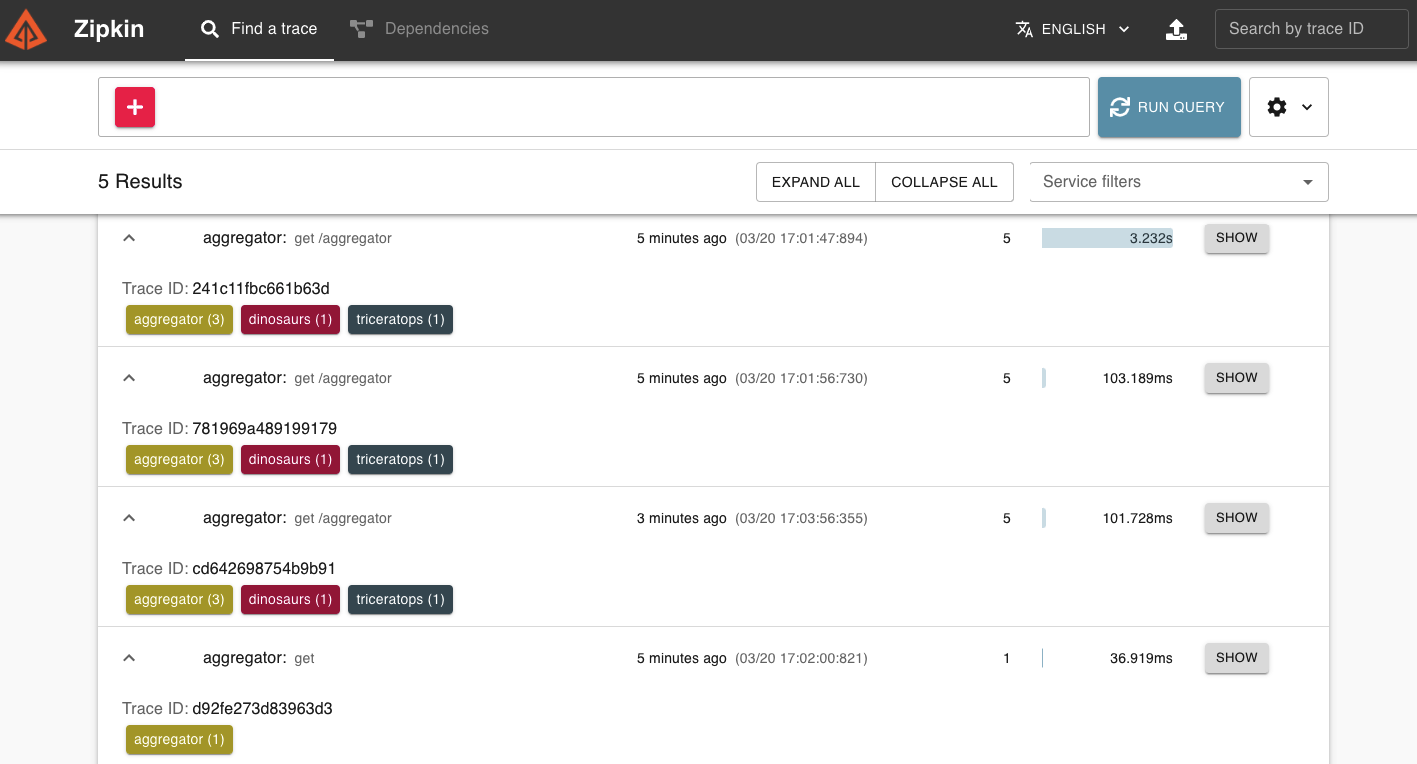
Ahí están todas las peticiones que hemos hecho a aggregator con su identificador (Trace ID), el tiempo que ha tardado cada una en ejecutarse y los microservicios por los que ha pasado.
Vamos a darle a SHOW para ver más información sobre la request cd642698754b9b91:
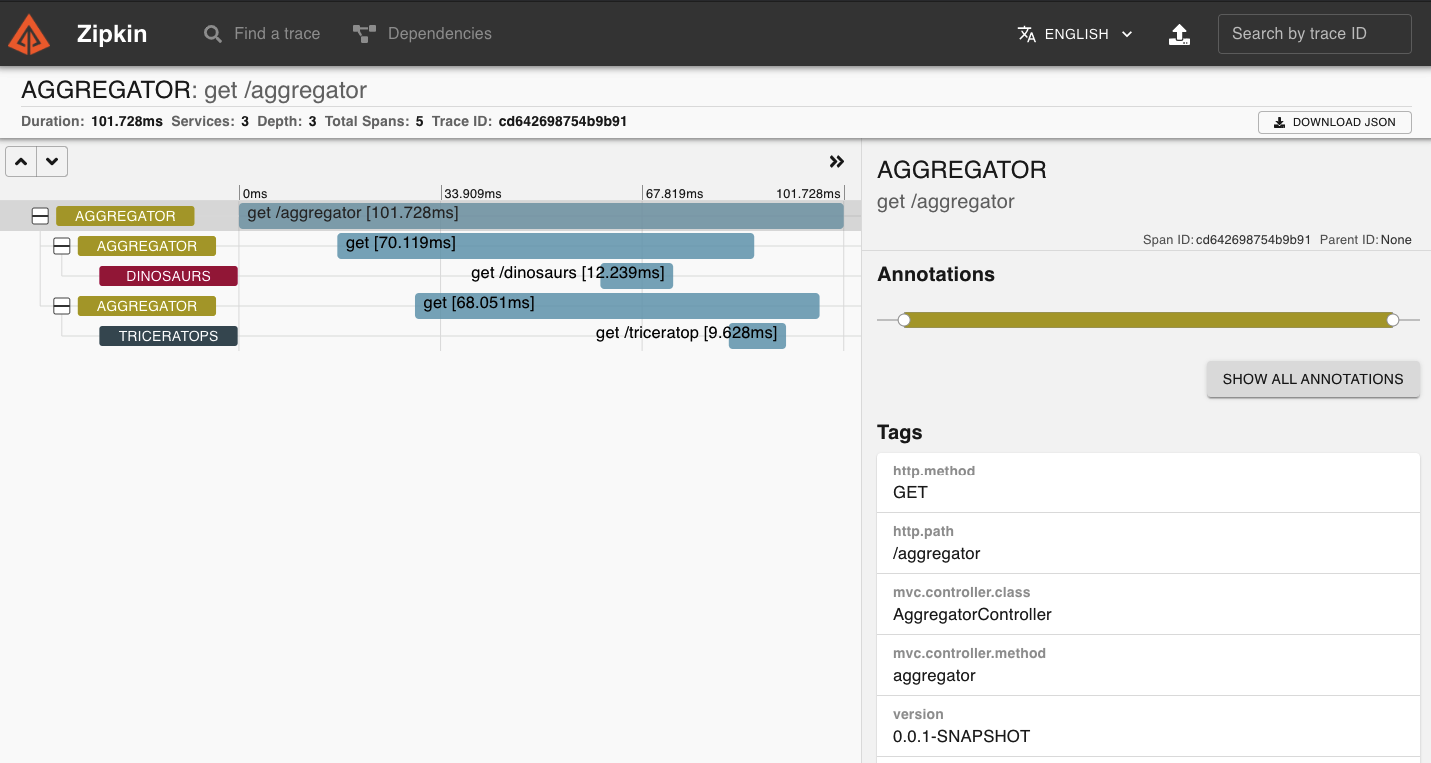
Como aggregator es un microservicio reactivo lo primero que ha hecho ha sido llamar a dinosaurs y en paralelo ha lanzado la llamada a triceratops sin bloquear ningún hilo de ejecución. Al obtener la respuesta de ambos ha compuesto la llamada y se la ha devuelto al cliente.
Otro detalle importante es el TAG con la versión de cada microservicio. Esta información es realmente util porque se puede identificar rápidamente si de pronto, al subir de versión uno de los microservicios, algo se ha roto y puedes avisar para que se haga un rollback a la versión en la que funcionaban tus llamadas.
Ahora vamos a tirar el microservicio de triceratops (cuyo container id es 82ca1b9e3998) y volvemos a lanzar la petición:
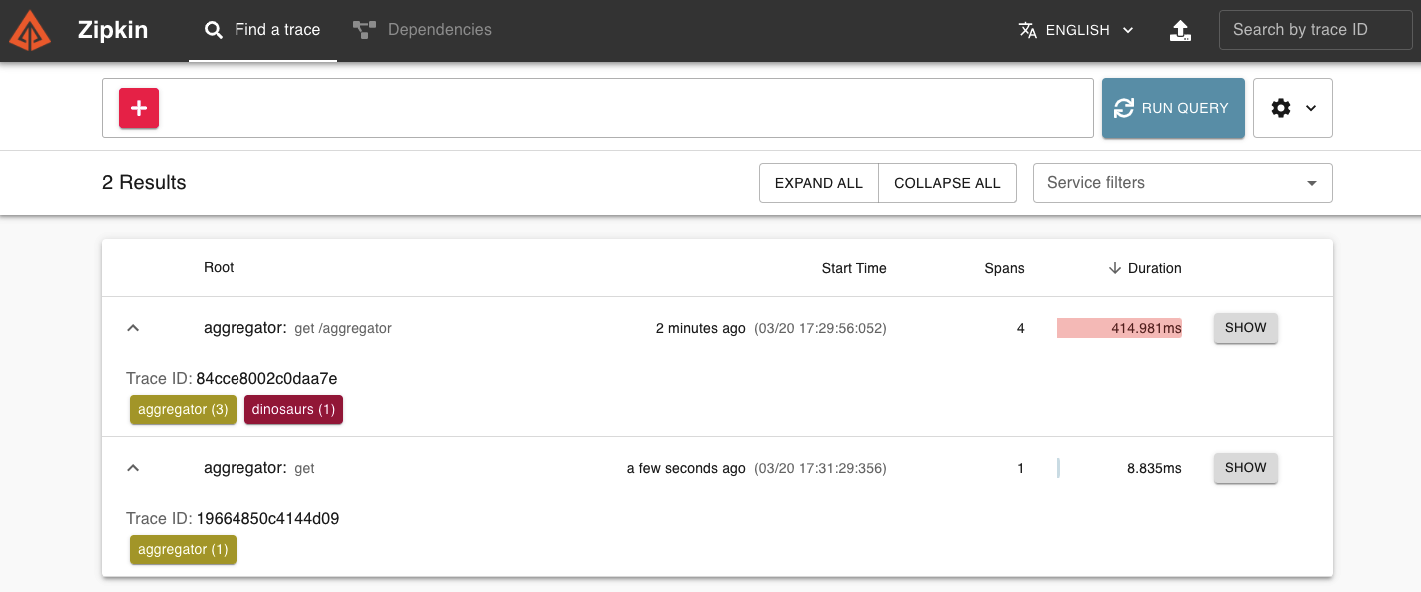
Ahí tenemos nuestra petición fallida en rojo ¿qué esconderá en su interior?
Pinchamos en la petición con Trace ID 84cce8002c0daa7e y en la llamada que ha dado error:
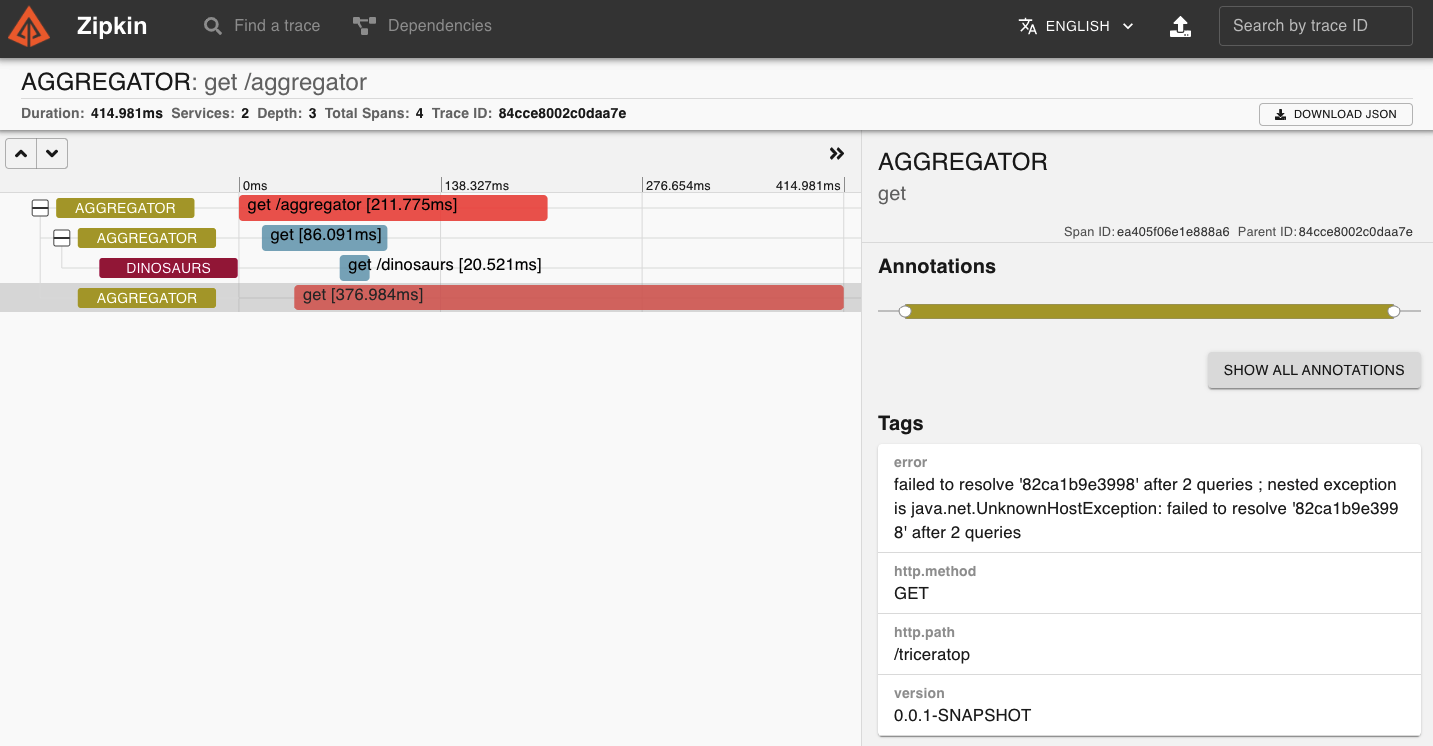
En los Tags tenemos la info del error que ha dado: UnknownHostException: failed to resolve ‘82ca1b9e3998’ Como tiramos el container con id 82ca1b9e3998 ahora no es capaz de encontrarlo.
Llamamos a los encargados de triceratops y les decimos que se les ha caido el microservicio. Revisan, arrancan y en cuestión de minutos ya tenemos la aplicación del dino park funcionando a la perfección.
Bonus track: Si en entonos previos a producción metemos una cabecera con el Trace-ID en las respuestas de los endpoints que son llamados desde el front, cada vez que dé error una petición podemos ir a tiro hecho y buscar en zipkin por el Trace ID, ver qué microservicio ha petado y llamar directamente al equipo encargado de él para solucionarlo lo antes posible.
Como habéis visto mantener arquitecturas de microservicios no es una tarea sencilla y para muchos será un nuevo paradigma.
Cuidad de vuestros contenedores y nos vemos en el próximo capítulo.
